


O Code, Where Art Thou
Or how to wrangle insights from a massive codebase…

Or how to wrangle insights from a massive codebase…
Music is a core part of my being. I have been a heavy metal musician, a college radio DJ, and traveled hundreds of miles to see my favorite bands. At my peak music obsession, I once had a collection of over 2,000 CD’s featuring over 20,000 songs.
Movies are also a big part of my life. When I find a combination of a great movie with a great soundtrack, the soundtrack is on repeat play for months on end. That was what happened when I watched the Coen Brother’s film O Brother, Where Art Thou and fell in love with the classic Americana folk music weaved throughout the movie.
One problem that comes with having a vast repository of music is that it is easy to forget songs and bands. There have been plenty of times when I would hear a familiar song and then wonder who did that song. Unless I am lucky enough to whip out my Soundhound app before the song ends, I am tortured for the rest of the day trying to recall the song.
That was the premise of a recent Reply All podcast episode. A listener called up asking if a popular song could possibly be erased from the Internet. His recollection of the tune was so detailed, he was able to direct a bunch of professional musicians to recreate a half-way decent version of the song.
I won’t spoil the ending, but popular songs do vanish from music history. Similarly, there is plenty of human knowledge that goes by the wayside, tossed away and never to be found again. We try to address this through wikis and documents and videos, but still manage to lose much of the context.
Facts are helpful, but what is more important is the backstory. For example, a laborious process at work that no one remembers why it exists or a tool you are still paying for but forgot why it was originally purchased (happens all too frequently in most companies).
The same happens to code. The problem is not so much that you forget the code, though that certainly is an issue with large codebases. It is more the case that you forgot what the code does or why certain decisions were made. Rarely does developer oriented documentation exist, so developers are left to sift through the sparse smattering of code comments, git history, and bug reports to get context.
Code comments deserve special attention here. This is because comments can have the opposite effect of providing context:
The developers are biased for being the authors, they don’t have the capability of judging their own work from an outsider perspective and that will lead to comments that other developers will find it hard to read.
We often forget as developers that the code we write should be able to explain how the code should work. In other words, if we have written clean, legible code, that should be enough for other developers to understand. Good code is self-documenting.
What code cannot easily explain is the “why”. That is analogous to unwritten rules, bad processes, and old files. We can see what it is, but we have lost the context behind the code. Context manifests itself in the following ways:
History — what is the story behind the code, who touched the code, and why certain decisions were made,
Value — what does the code add to the overall functionality of the product, how is it contributing to usability and business expectations, is it still useful,
Impact — how does this code impact other aspects of code and functionality, what other code does this piece of code depend upon,
Quality — does the code produce proper and expected results, does it contribute to maintainability, has it been tested and verified.
Some of this can be addressed by code search utilities. A decent tool can read code and code artifacts such as commit messages, log files, tests, etc. A better tool can read code across repositories and different languages, which is necessary for large codebases and legacy software. To get to the complete understanding of code from a history, value, impact and quality perspective however requires something deeper.
The reality of modern software development is growing code complexity. A simple mobile app may only be several thousand lines of code. Today’s browsers are several million lines of code and operating systems are often in the tens of millions of lines of code. The software in cars is now over hundred million lines of code. Google manages two billion lines of code, all in a single repository.
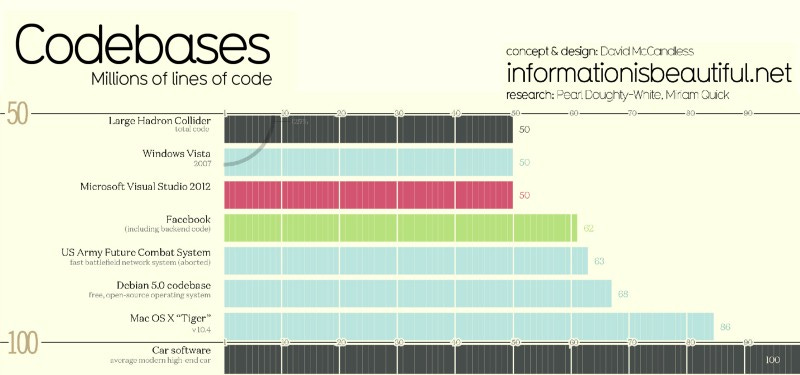
These are extreme examples, but even a modestly robust product will exhibit high code complexity. Whether a mature startup with a hundred developers or an enterprise with tens of thousands of developers, all are impacted by the volume of code and the dependencies in the code. A single change to an API for example can ripple across multiple other functions and products, requiring careful changes to the code and the corresponding tests.
The other area that adds to code complexity is the rate of change. Modern engineering practices and DevOps tooling enables developers to commit code into production multiple times a day. At the scale of Google, that means over 20,000 commits per day.
With growing size and increasing speed, engineering teams now must contend with impacts to productivity and risk. It is easy to see how a critical security protocol could be missed or how a growing backlog of unanswered questions can slow down release cycles.
Productivity can be particularly tricky to solve. When I speak with engineering teams, the most common questions they grapple with are “where is X”, “who knows about Y”, and “if Z changes, what happens”. Some answers can be surfaced through search, but often what is required is the deeper context such as who is the real expert or what might break if a change is made.

This is where AI can address code complexity, and help provide the context that is increasingly important to grasp. Whereas other solutions either slow down agility or lack the ability to unlock contextual understanding, AI augments our understanding of the “why” behind the code and impact of code changes without losing agility and productivity.
How so? AI can be applied to code to understand core business and technical semantics, such as how code supports certain functionality or the technical capabilities enabled through code. These tags can be analyzed to understand associations, giving deeper context around code. And finally by applying these models to significant codebases, the relevancy rates can be improved as the model learns new concepts and patterns.
Contextual understanding of code is the next significant opportunity to raise the bar on code quality and engineering productivity. There will still be value in human-based knowledge and community generated content. But increasingly we need the power and speed of AI to give us a boost as the growing complexity of code overwhelms our ability to effectively manage and maintain large codebases.
What are some of the most common questions you face when coding? How is your organization handling the challenges of increasing code complexity?

Episode #3 — Ross Clanton on roadblocks & roadkill in DevOps adoption
The Heretechs
Episode #3 - Roadblocks and roadkill in DevOps adoption Co-hosts Justin Arbuckle and Mark Birch welcome guest Ross…heretechs.io
Revisiting our past episodes before we start on our next series of podcast episodes, this one featuring Ross Clanton who led Verizon on their engineering transformation!
Check out past podcast episodes on Apple Podcasts, Google Podcast, or wherever you listen to your favorite podcasts. Please like and subscribe 😁
We help IT leaders in enterprises solve the cultural challenges involved in digital transformation and move towards a community based culture that delivers innovation and customer value faster. Learn more about our work here.